
笔记内容来源:拉勾教育数据分析实战训练营拉勾教育的初心和用户体验值得点赞我自己在教育行业8年,也见惯了一些教育行业公司只抓销售但不重视用户体验和服务,交钱前各种频繁跟进,交钱后失联和前期过度承诺的都化作泡影。从我个人的体验来看, 拉勾教育是可靠的,课程提供7天的试学, 不满意可以全额退款。课程内容迭代优化的速度很快,教研不断的再优化课程体验。更靠谱的是,课程是终身有效的,给后面回顾课程提供了大大的方便。之前内容回顾:8 数据重塑import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0,100,size = (10,3)),
index = list('ABCDEFHIJK'),
columns=['Python','Tensorflow','Keras'])
# 转置,行列变换
df.T
df2 = pd.DataFrame(data = np.random.randint(0,100,size = (20,3)),
columns=['Python','Tensorflow','Keras'],
index = pd.MultiIndex.from_product([list('ABCDEFHIJK'),['期中','期末']])) #多层索引
# ⾏旋转成列麻将桌,level指定哪⼀层麻将桌,进⾏变换
df2.unstack(level = -1) # 行索引变成列索引,-1表示最后一层(从外到内,正着数;从内到外,倒着数)
# 列旋转成⾏
df2.stack()
# ⾏列互换
df2.stack().unstack(level = 1)
# 多层索引DataFrame数学计算
df2.mean() # 各学科平均分
df2.mean(level=0) # 各学科,每个⼈期中期末平均分
df2.mean(level = 1) # 各学科,期中期末所有⼈平均分 练习9 数学和统计⽅法pandas对象拥有⼀组常⽤的数学和统计⽅法。它们属于汇总统计,对Series汇总计算获取mean、max值或者对DataFrame⾏、列汇总计算返回⼀个Series。9.1 简单统计指标import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0,100,size = (20,3)),
index = list('ABCDEFHIJKLMNOPQRSTU'),
columns=['Python','Tensorflow','Keras'])
# 1、简单统计指标。默认计算axis=0,即每⼀列
df.count() # 统计非空值的数量
df.max(axis = 0) #轴0最⼤值,即每⼀列最⼤值
df.min() # 默认计算轴0最⼩值
df.median() # 中位数
df.sum() # 求和
df.mean(axis = 1) #轴1平均值,即每⼀⾏的平均值
df.quantile(q = 0.5) # 获取中位数
df.quantile(q = [0,0.25,0.5,0.75,1]) # 获取4分位数
df.quantile(q = [0.2,0.4,0.8]) # 分位数
df.describe() # 查看数值型列的汇总统计,计数、平均值、标准差、最⼩值、四分位数、最⼤值
df['Python'].unique() # 去除重复数据
df['Python'].value_counts() # 统计出现的频次 练习9 数学和统计⽅法pandas对象拥有⼀组常⽤的数学和统计⽅法。它们属于汇总统计,对Series汇总计算获取mean、max值或者对DataFrame⾏、列汇总计算返回⼀个Series。9.1 简单统计指标import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0,100,size = (20,3)),
index = list('ABCDEFHIJKLMNOPQRSTU'),
columns=['Python','Tensorflow','Keras'])
# 1、简单统计指标。默认计算axis=0,即每⼀列
df.count() # 统计非空值的数量
df.max(axis = 0) #轴0最⼤值,即每⼀列最⼤值
df.min() # 默认计算轴0最⼩值
df.median() # 中位数
df.sum() # 求和
df.mean(axis = 1) #轴1平均值,即每⼀⾏的平均值
df.quantile(q = 0.5) # 获取中位数
df.quantile(q = [0,0.25,0.5,0.75,1]) # 获取4分位数
df.quantile(q = [0.2,0.4,0.8]) # 分位数
df.describe() # 查看数值型列的汇总统计,计数、平均值、标准差、最⼩值、四分位数、最⼤值
df['Python'].unique() # 去除重复数据
df['Python'].value_counts() # 统计出现的频次 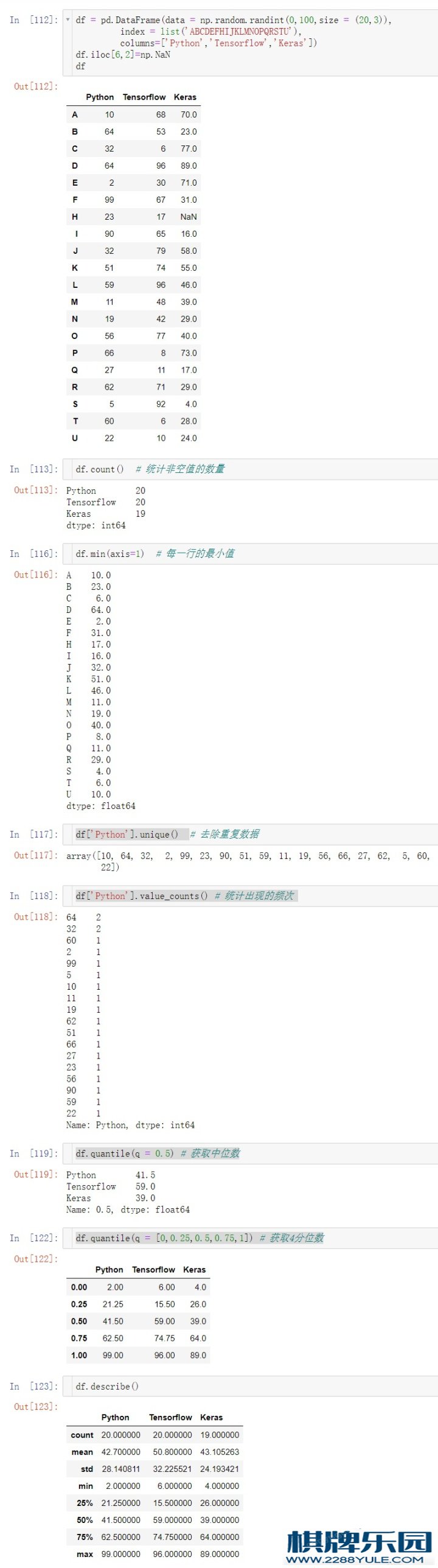 练习9.2 索引标签、位置获取# 2、索引位置
df['Python'].argmin() # 返回第一个最⼩值位置
df['Keras'].argmax() # 返回第一个最⼤值位置
df['Python'].idxmax() # 返回Python列最大值的索引标签
df.idxmax() # 返回最⼤值的索引标签
df.idxmin() # 返回最⼩值的索引标签 练习9.2 索引标签、位置获取# 2、索引位置
df['Python'].argmin() # 返回第一个最⼩值位置
df['Keras'].argmax() # 返回第一个最⼤值位置
df['Python'].idxmax() # 返回Python列最大值的索引标签
df.idxmax() # 返回最⼤值的索引标签
df.idxmin() # 返回最⼩值的索引标签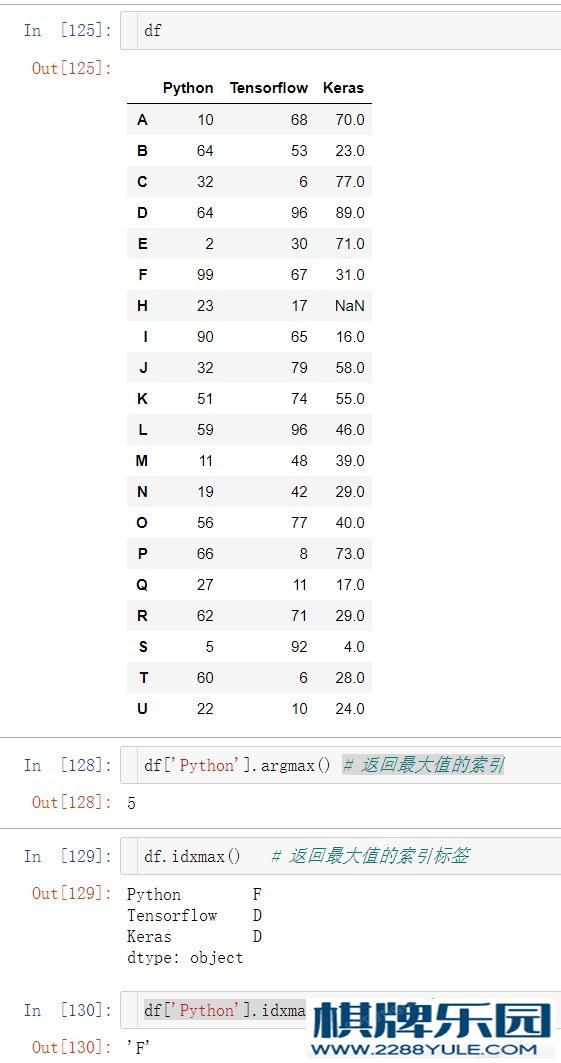 练习9.3 更多统计指标# 3、更多统计指标
df['Python'].value_counts() # 统计元素出现次数
df['Keras'].unique() # 去重
df.cumsum() # 累加
df.cumprod() # 累乘
df.std() # 标准差
df.var() # ⽅差
df.cummin() # 累计最⼩值
df.cummax() # 累计最⼤值
df.diff() # 计算差分,当前数据减去上一个的差值
df.pct_change() # 计算百分⽐变化 练习9.3 更多统计指标# 3、更多统计指标
df['Python'].value_counts() # 统计元素出现次数
df['Keras'].unique() # 去重
df.cumsum() # 累加
df.cumprod() # 累乘
df.std() # 标准差
df.var() # ⽅差
df.cummin() # 累计最⼩值
df.cummax() # 累计最⼤值
df.diff() # 计算差分,当前数据减去上一个的差值
df.pct_change() # 计算百分⽐变化 练习9.4 ⾼级统计指标# 4、⾼级统计指标
df.cov() # 属性的协⽅差
df['Python'].cov(df['Keras']) # Python和Keras的协⽅差
df.corr() # 所有属性相关性系数
df.corrwith(df['Tensorflow']) # 单⼀属性相关性系数,一列的相关性系数 练习9.4 ⾼级统计指标# 4、⾼级统计指标
df.cov() # 属性的协⽅差
df['Python'].cov(df['Keras']) # Python和Keras的协⽅差
df.corr() # 所有属性相关性系数
df.corrwith(df['Tensorflow']) # 单⼀属性相关性系数,一列的相关性系数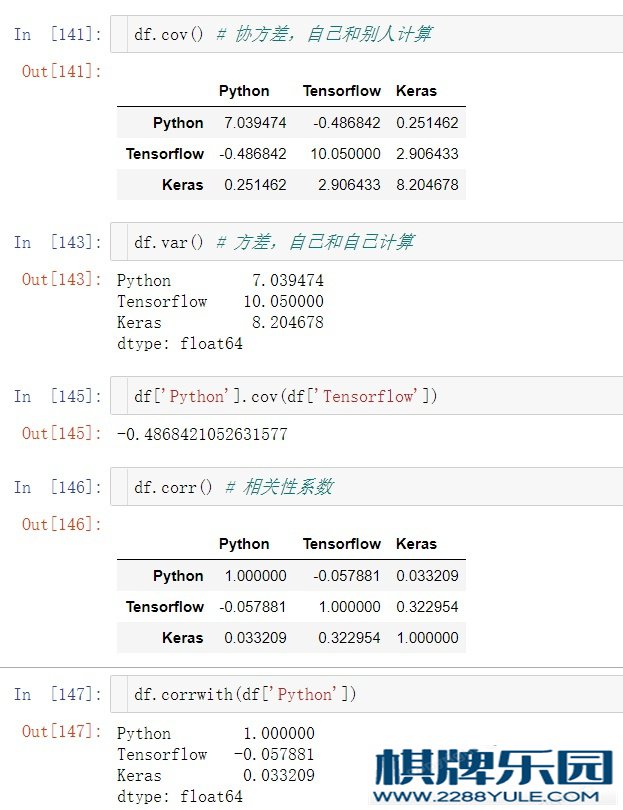 练习10 数据排序import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0,30,size = (30,3)),
index = list('qwertyuioijhgfcasdcvbnerfghjcf'),
columns = ['Python','Keras','Pytorch'])
# 1、索引列名排序
df.sort_index(axis = 0,ascending=True) # 按索引排序,升序
df.sort_index(axis = 1,ascending=False) #按列名排序,降序
# 2、属性值排序
df.sort_values(by = ['Python']) #按Python属性值升序
df.sort_values(by=['Python'],ascending=True) #按Python属性值升序
df.sort_values(by = ['Python','Keras'])#先按Python,再按Keras排序
# 3、返回属性n⼤或者n⼩的值
df.nlargest(n = 10,columns='Keras') # 根据属性Keras排序,返回最⼤10个数据
df.nsmallest(5,columns='Python') # 根据属性Python排序,返回最⼩5个数据
df.nsmallest(10,columns=['Python','Keras']) #先按Python,再按Keras排序,返回最小10个数据 练习10 数据排序import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0,30,size = (30,3)),
index = list('qwertyuioijhgfcasdcvbnerfghjcf'),
columns = ['Python','Keras','Pytorch'])
# 1、索引列名排序
df.sort_index(axis = 0,ascending=True) # 按索引排序,升序
df.sort_index(axis = 1,ascending=False) #按列名排序,降序
# 2、属性值排序
df.sort_values(by = ['Python']) #按Python属性值升序
df.sort_values(by=['Python'],ascending=True) #按Python属性值升序
df.sort_values(by = ['Python','Keras'])#先按Python,再按Keras排序
# 3、返回属性n⼤或者n⼩的值
df.nlargest(n = 10,columns='Keras') # 根据属性Keras排序,返回最⼤10个数据
df.nsmallest(5,columns='Python') # 根据属性Python排序,返回最⼩5个数据
df.nsmallest(10,columns=['Python','Keras']) #先按Python,再按Keras排序,返回最小10个数据 练习11 分箱操作分箱操作就是将连续数据转换为分类对应物的过程。⽐如将连续的身⾼数据划分为:矮中⾼。分箱操作分为等距分箱和等频分箱。分箱操作也叫⾯元划分或者离散化。import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0,150,size = (100,3)),
columns=['Python','Tensorflow','Keras'])
# 1、等宽分箱
pd.cut(df.Python,bins = 3)
# 指定宽度分箱
pd.cut(df.Keras,#分箱数据
bins = [0,60,90,120,150],#分箱断点
right = False, # 左闭右开,默认True左开右闭
labels=['不及格','中等','良好','优秀'])# 分箱后分类
# 2、等频分箱
pd.qcut(df.Python,q = 4,# 4等分
labels=['差','中','良','优']) # 分箱后分类 练习11 分箱操作分箱操作就是将连续数据转换为分类对应物的过程。⽐如将连续的身⾼数据划分为:矮中⾼。分箱操作分为等距分箱和等频分箱。分箱操作也叫⾯元划分或者离散化。import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0,150,size = (100,3)),
columns=['Python','Tensorflow','Keras'])
# 1、等宽分箱
pd.cut(df.Python,bins = 3)
# 指定宽度分箱
pd.cut(df.Keras,#分箱数据
bins = [0,60,90,120,150],#分箱断点
right = False, # 左闭右开,默认True左开右闭
labels=['不及格','中等','良好','优秀'])# 分箱后分类
# 2、等频分箱
pd.qcut(df.Python,q = 4,# 4等分
labels=['差','中','良','优']) # 分箱后分类 练习12 分组聚合 练习12 分组聚合 12.1 分组import numpy as np
import pandas as pd
# 准备数据
df = pd.DataFrame(data = {'sex':np.random.randint(0,2,size = 300), # 0男,1⼥
'class':np.random.randint(1,9,size = 300),#1~8⼋个班
'Python':np.random.randint(0,151,size = 300),#Python成绩
'Keras':np.random.randint(0,151,size =300),#Keras成绩
'Tensorflow':np.random.randint(0,151,size=300),
'Java':np.random.randint(0,151,size = 300),
'C++':np.random.randint(0,151,size = 300)})
df['sex'] = df['sex'].map({0:'男',1:'⼥'}) # 将0,1映射成男⼥
# 1、分组->可迭代对象
# 1.1 先分组再获取数据
g = df.groupby(by = 'sex') # 单分组
g = df.groupby(by='sex')['Python'] # 单分组,显示指定列
g = df.groupby(by='sex').Python # 单分组,显示指定列
for name,data in g:
print('组名:',name)
print('数据:',data)
df.groupby(by = ['class','sex']) # 多分组
df.groupby(by = ['class','sex'])['Python'] # 多分组,显示指定列
# 1.2 对⼀列值进⾏分组
df['Python'].groupby(df['class']) # 单分组
df['Keras'].groupby([df['class'],df['sex']]) # 多分组,class8,性别2,共16组
# 1.3 按数据类型分组
df.groupby(df.dtypes,axis = 1)
# 1.4 通过字典进⾏分组
m ={'sex':'category','class':'category','Python':'IT','Keras':'IT','Tensorflow':'IT','Java':'IT','C++':'IT'}
for name,data in df.groupby(m,axis = 1):
print('组名',name)
print('数据',data) 12.1 分组import numpy as np
import pandas as pd
# 准备数据
df = pd.DataFrame(data = {'sex':np.random.randint(0,2,size = 300), # 0男,1⼥
'class':np.random.randint(1,9,size = 300),#1~8⼋个班
'Python':np.random.randint(0,151,size = 300),#Python成绩
'Keras':np.random.randint(0,151,size =300),#Keras成绩
'Tensorflow':np.random.randint(0,151,size=300),
'Java':np.random.randint(0,151,size = 300),
'C++':np.random.randint(0,151,size = 300)})
df['sex'] = df['sex'].map({0:'男',1:'⼥'}) # 将0,1映射成男⼥
# 1、分组->可迭代对象
# 1.1 先分组再获取数据
g = df.groupby(by = 'sex') # 单分组
g = df.groupby(by='sex')['Python'] # 单分组,显示指定列
g = df.groupby(by='sex').Python # 单分组,显示指定列
for name,data in g:
print('组名:',name)
print('数据:',data)
df.groupby(by = ['class','sex']) # 多分组
df.groupby(by = ['class','sex'])['Python'] # 多分组,显示指定列
# 1.2 对⼀列值进⾏分组
df['Python'].groupby(df['class']) # 单分组
df['Keras'].groupby([df['class'],df['sex']]) # 多分组,class8,性别2,共16组
# 1.3 按数据类型分组
df.groupby(df.dtypes,axis = 1)
# 1.4 通过字典进⾏分组
m ={'sex':'category','class':'category','Python':'IT','Keras':'IT','Tensorflow':'IT','Java':'IT','C++':'IT'}
for name,data in df.groupby(m,axis = 1):
print('组名',name)
print('数据',data) 练习12.2 分组聚合2、分组直接调⽤函数进⾏聚合
# 按照性别分组,其他列均值聚合
df.groupby(by = 'sex').mean().round(1) # 保留1位⼩数
# 按照班级和性别进⾏分组,Python、Keras的最⼤值聚合
df.groupby(by = ['class','sex'])[['Python','Keras']].max()
# 按照班级和性别进⾏分组,计数聚合。统计每个班,男⼥⼈数
df.groupby(by = ['class','sex']).size()
# 基本描述性统计聚合
df.groupby(by = ['class','sex']).describe() 练习12.2 分组聚合2、分组直接调⽤函数进⾏聚合
# 按照性别分组,其他列均值聚合
df.groupby(by = 'sex').mean().round(1) # 保留1位⼩数
# 按照班级和性别进⾏分组,Python、Keras的最⼤值聚合
df.groupby(by = ['class','sex'])[['Python','Keras']].max()
# 按照班级和性别进⾏分组,计数聚合。统计每个班,男⼥⼈数
df.groupby(by = ['class','sex']).size()
# 基本描述性统计聚合
df.groupby(by = ['class','sex']).describe() 练习12.3 分组聚合apply、transform 练习12.3 分组聚合apply、transform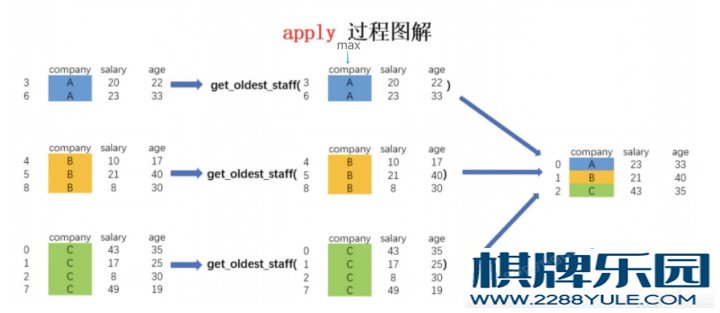  # 3、分组后调⽤apply,transform封装单⼀函数计算
# apply返回聚合结果
df.groupby(by = ['class','sex'])[['Python','Keras']].apply(np.mean).round(1)
# transform返回全数据,返回DataFrame.shape和原DataFrame.shape⼀样
def normalization(x):
return (x - x.min())/(x.max() - x.min()) # 最⼤值最⼩值归⼀化
df.groupby(by = ['class','sex'])[['Python','Tensorflow']].transform(normalization).round(3) # 3、分组后调⽤apply,transform封装单⼀函数计算
# apply返回聚合结果
df.groupby(by = ['class','sex'])[['Python','Keras']].apply(np.mean).round(1)
# transform返回全数据,返回DataFrame.shape和原DataFrame.shape⼀样
def normalization(x):
return (x - x.min())/(x.max() - x.min()) # 最⼤值最⼩值归⼀化
df.groupby(by = ['class','sex'])[['Python','Tensorflow']].transform(normalization).round(3) 练习12.4 分组聚合agg 练习12.4 分组聚合agg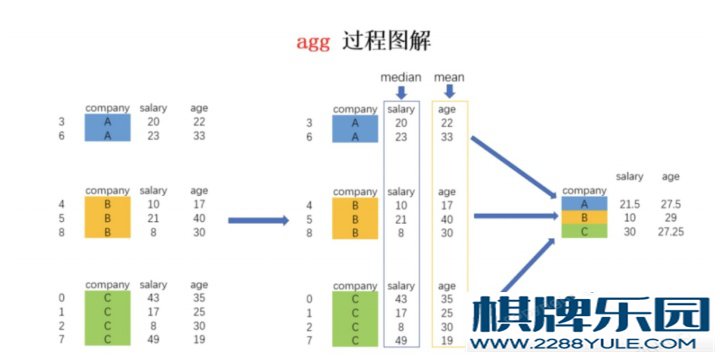 # 4、agg 多中统计汇总操作
# 分组后调⽤agg应⽤多种统计汇总
df.groupby(by = ['class','sex'])[['Tensorflow','Keras']].agg([np.max,np.min,pd.Series.count])
# 分组后不同属性应⽤多种不同统计汇总
df.groupby(by = ['class','sex'])[['Python','Keras']].agg({'Python':[('最⼤值',np.max),('最⼩值',np.min)],
'Keras':[('计 数',pd.Series.count),('中位数',np.median)]}) # 4、agg 多中统计汇总操作
# 分组后调⽤agg应⽤多种统计汇总
df.groupby(by = ['class','sex'])[['Tensorflow','Keras']].agg([np.max,np.min,pd.Series.count])
# 分组后不同属性应⽤多种不同统计汇总
df.groupby(by = ['class','sex'])[['Python','Keras']].agg({'Python':[('最⼤值',np.max),('最⼩值',np.min)],
'Keras':[('计 数',pd.Series.count),('中位数',np.median)]})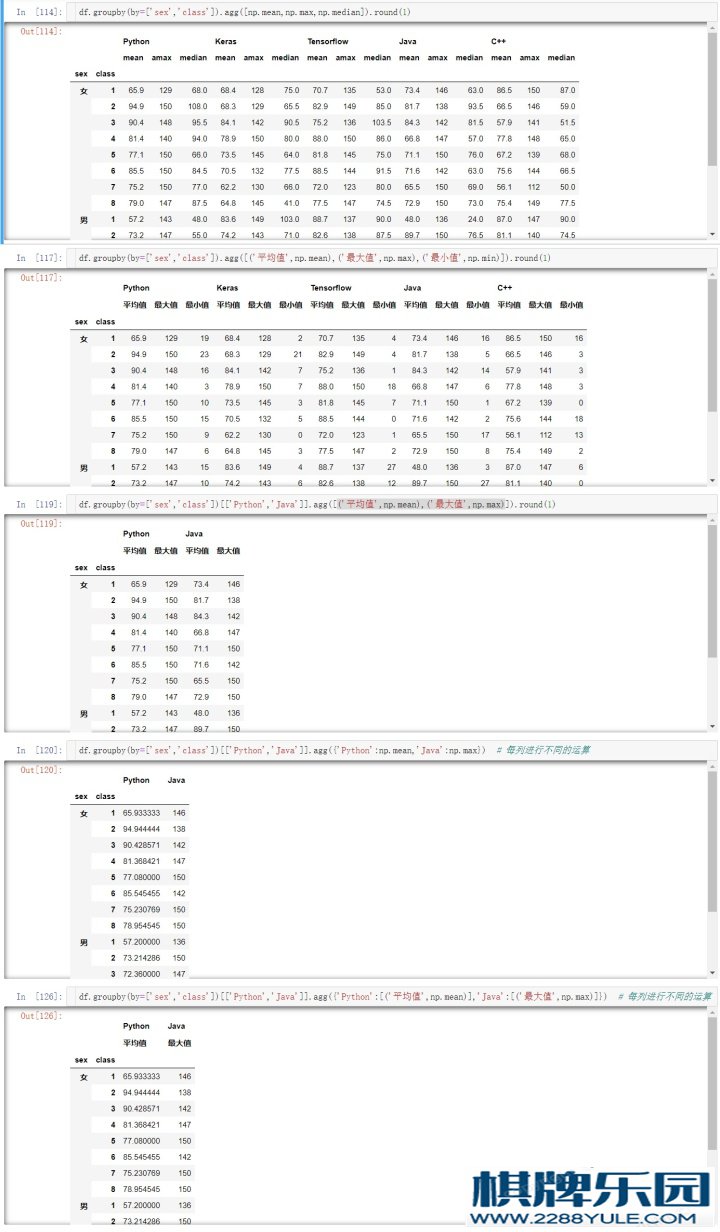 练习12.5 透视表pivot_table# 5、透视表
# 透视表也是⼀种分组聚合运算
def count(x):
return len(x)
df.pivot_table(values=['Python','Keras','Tensorflow'],# 要透视分组的值
index=['class','sex'], # 分组透视指标
aggfunc={'Python':[('最⼤值',np.max)], # 聚合运算
'Keras':[('最⼩值',np.min),('中位数',np.median)],
'Tensorflow':[('最⼩值',np.min),('平均值',np.mean),('计 数',count)]}) 练习12.5 透视表pivot_table# 5、透视表
# 透视表也是⼀种分组聚合运算
def count(x):
return len(x)
df.pivot_table(values=['Python','Keras','Tensorflow'],# 要透视分组的值
index=['class','sex'], # 分组透视指标
aggfunc={'Python':[('最⼤值',np.max)], # 聚合运算
'Keras':[('最⼩值',np.min),('中位数',np.median)],
'Tensorflow':[('最⼩值',np.min),('平均值',np.mean),('计 数',count)]}) 练习13 时间序列13.1 时间戳操作# 1、创建⽅法
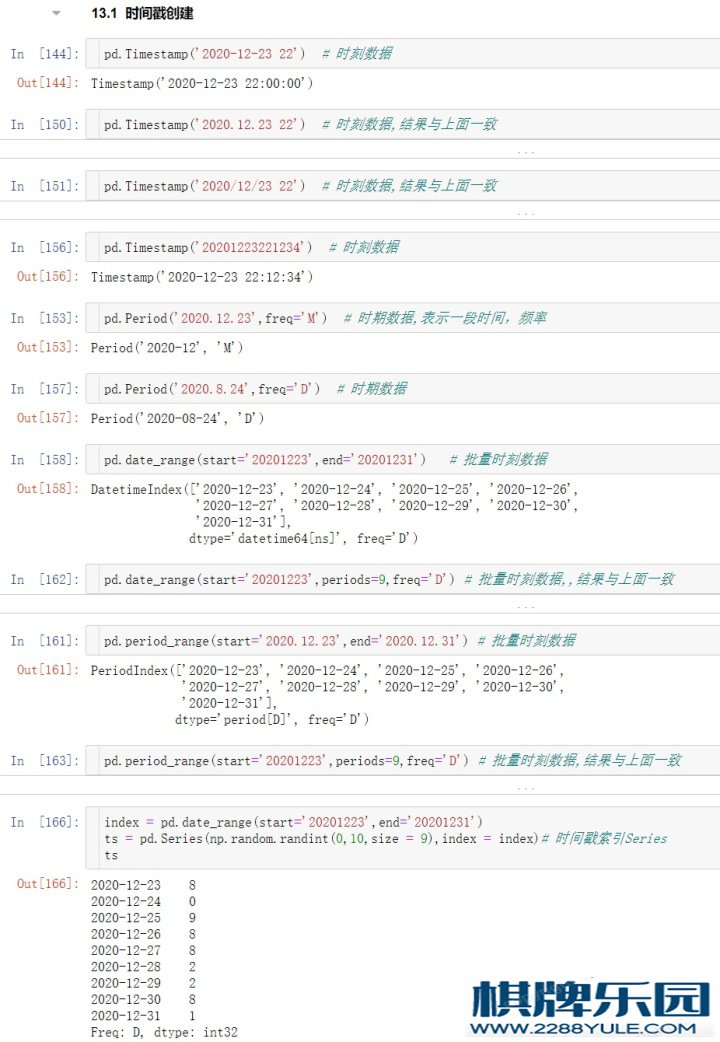
pd.Timestamp('2020-12-23 22') # 时刻数据
pd.Timestamp('2020.12.23 22') # 时刻数据
pd.Timestamp('2020/12/23 22') # 时刻数据
pd.Timestamp('20201223221234') # 时刻数据
pd.Period('2020-8-24',freq = 'M') # 时期数据
pd.Period('2020.8.24',freq='D') # 时期数据
index = pd.date_range('2020.08.24',periods=5,freq = 'M') # 批量时刻数据
pd.date_range(start='20201223',end='20201231')
pd.period_range('2020.08.24',periods=5,freq='M') # 批量时期数据
ts = pd.Series(np.random.randint(0,10,size = 5),index = index) # 时间戳索引Series
练习13 时间序列13.1 时间戳操作# 1、创建⽅法
pd.Timestamp('2020-12-23 22') # 时刻数据
pd.Timestamp('2020.12.23 22') # 时刻数据
pd.Timestamp('2020/12/23 22') # 时刻数据
pd.Timestamp('20201223221234') # 时刻数据
pd.Period('2020-8-24',freq = 'M') # 时期数据
pd.Period('2020.8.24',freq='D') # 时期数据
index = pd.date_range('2020.08.24',periods=5,freq = 'M') # 批量时刻数据
pd.date_range(start='20201223',end='20201231')
pd.period_range('2020.08.24',periods=5,freq='M') # 批量时期数据
ts = pd.Series(np.random.randint(0,10,size = 5),index = index) # 时间戳索引Series
 练习# 2、转换⽅法
pd.to_datetime(['2020.08.24','2020-08-24','24/08/2020','2020/8/24']) # 时间戳的转换
pd.to_datetime([1598582232],unit='s')
dt = pd.to_datetime([1598582420401],unit = 'ms') # 世界标准时间
dt + pd.DateOffset(hours = 8) # 东⼋区时间
dt + pd.DateOffset(days = 100) # 100天后⽇期 练习# 2、转换⽅法
pd.to_datetime(['2020.08.24','2020-08-24','24/08/2020','2020/8/24']) # 时间戳的转换
pd.to_datetime([1598582232],unit='s')
dt = pd.to_datetime([1598582420401],unit = 'ms') # 世界标准时间
dt + pd.DateOffset(hours = 8) # 东⼋区时间
dt + pd.DateOffset(days = 100) # 100天后⽇期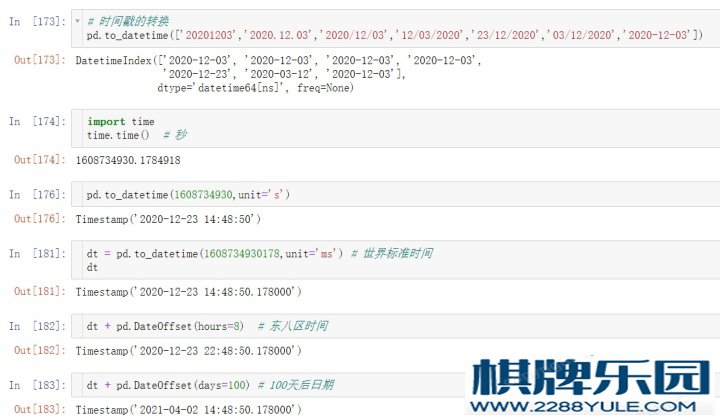 练习13.2 时间戳索引index = pd.date_range("2020-8-24",)
ts = pd.Series(range(len(index)), index=index)
# str类型索引
ts['2020-08-30'] # ⽇期访问数据
ts['2020-08-24':'2020-09-3'] # ⽇期切⽚
ts['2020-08'] # 传⼊年⽉
ts['2020'] # 传⼊年 练习13.2 时间戳索引index = pd.date_range("2020-8-24",)
ts = pd.Series(range(len(index)), index=index)
# str类型索引
ts['2020-08-30'] # ⽇期访问数据
ts['2020-08-24':'2020-09-3'] # ⽇期切⽚
ts['2020-08'] # 传⼊年⽉
ts['2020'] # 传⼊年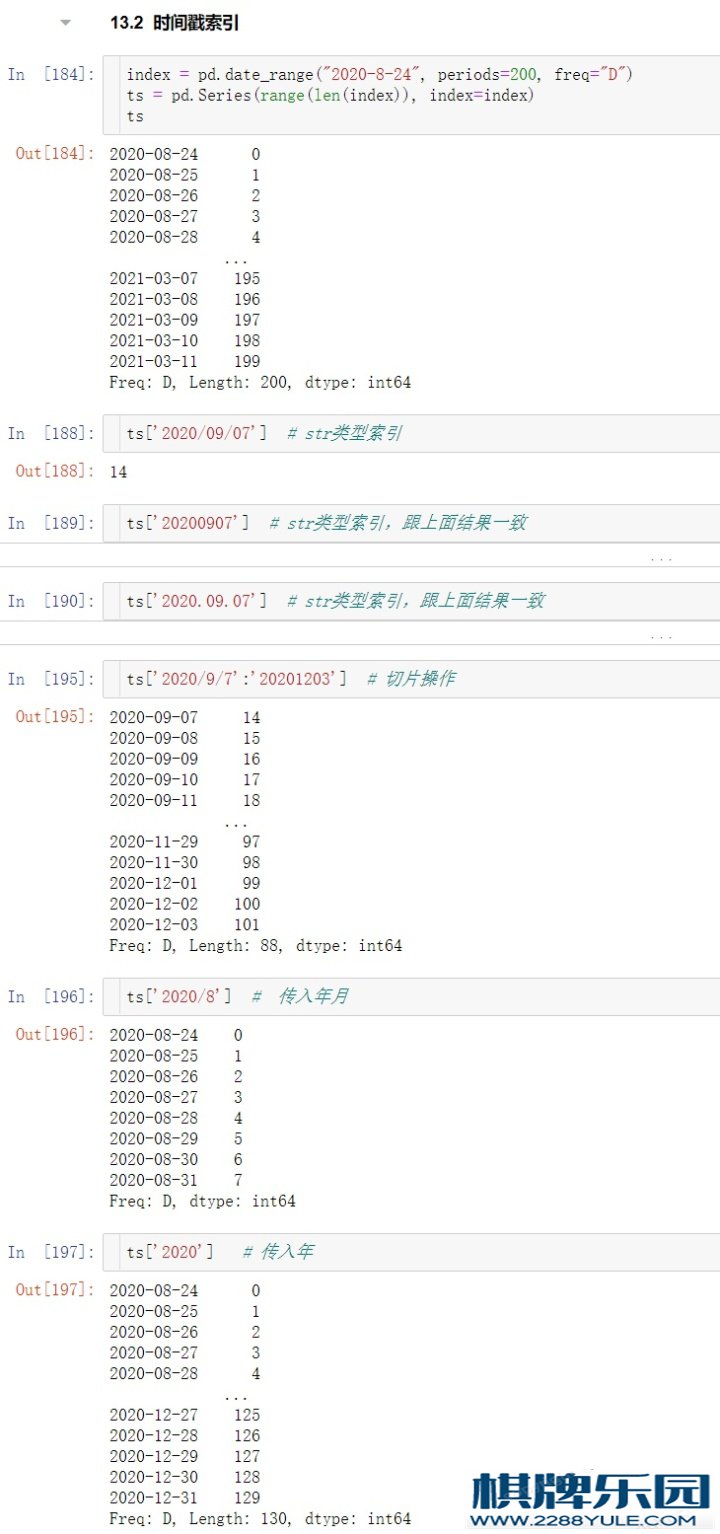 # 时间戳索引
ts[pd.Timestamp('2020-08-30')]
ts[pd.Timestamp('2020-08-24'):pd.Timestamp('2020-08-30')] # 切⽚
ts[pd.date_range('2020-08-24',periods=10,freq='D')] # 时间戳索引
ts[pd.Timestamp('2020-08-30')]
ts[pd.Timestamp('2020-08-24'):pd.Timestamp('2020-08-30')] # 切⽚
ts[pd.date_range('2020-08-24',periods=10,freq='D')]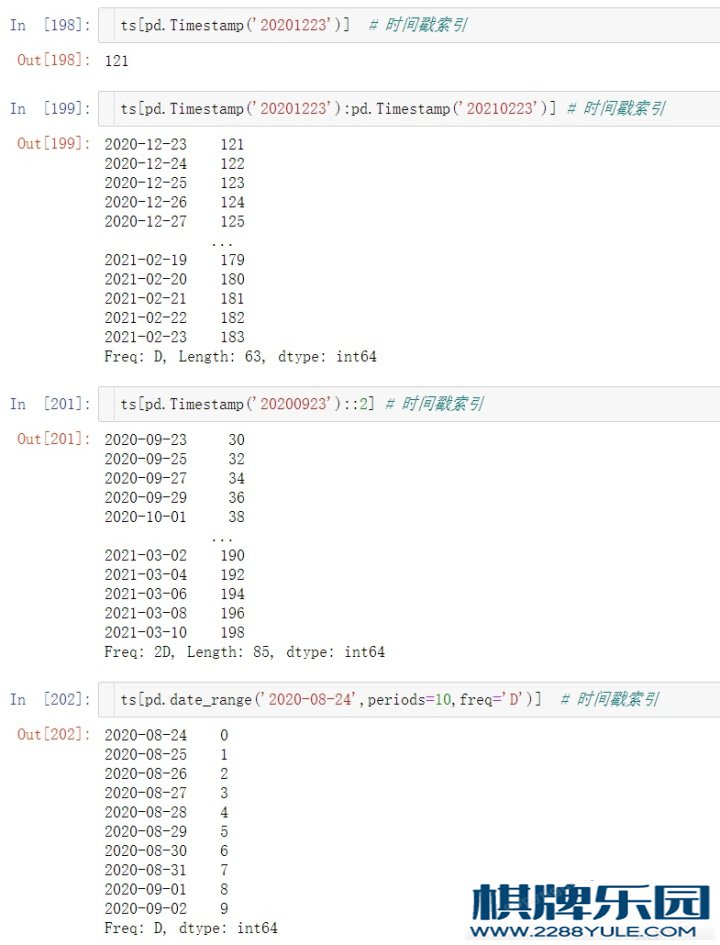 # 时间戳索引属性
ts.index.year # 获取年
ts.index.dayofweek # 获取星期⼏
ts.index.weekofyear # ⼀年中第⼏个星期⼏ # 时间戳索引属性
ts.index.year # 获取年
ts.index.dayofweek # 获取星期⼏
ts.index.weekofyear # ⼀年中第⼏个星期⼏ 13.3 时间序列常⽤⽅法在做时间序列相关的⼯作时,经常要对时间做⼀些移动/滞后、频率转换、采样等相关操作,我们来看下这些操作如何使⽤index = pd.date_range('8/1/2020', periods=365, freq='D')
ts = pd.Series(np.random.randint(0, 500, len(index)), index=index)
# 1、移动
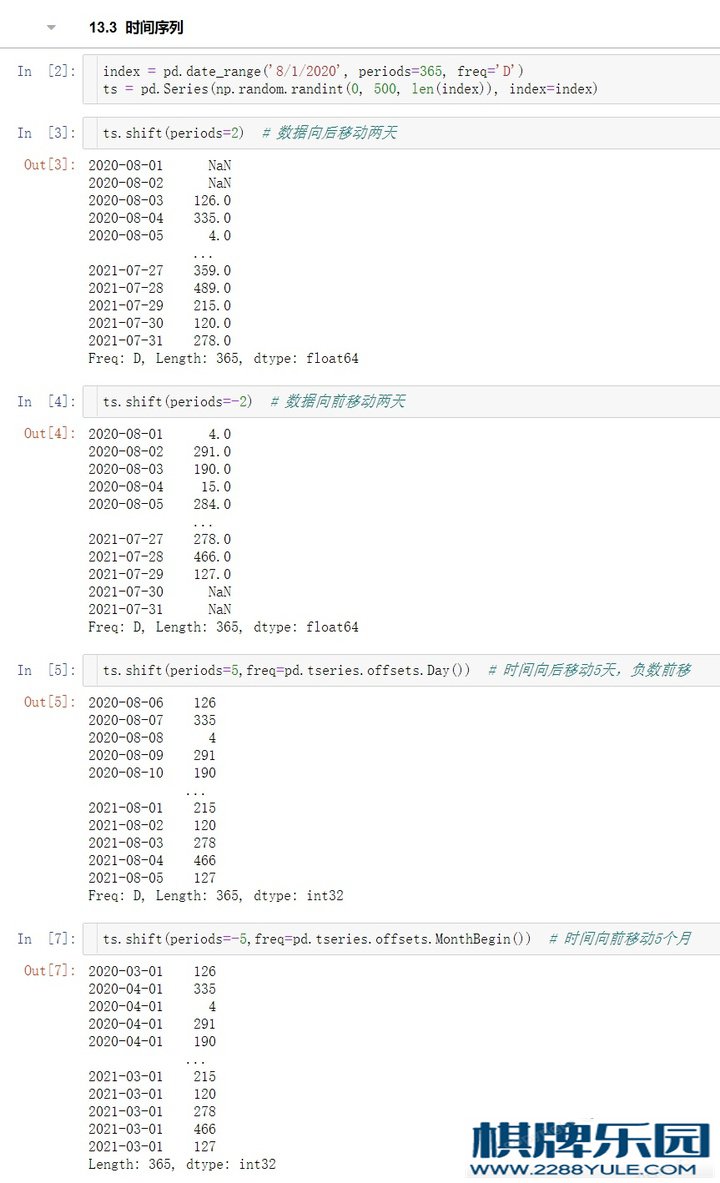
ts.shift(periods = 2) # 数据后移
ts.shift(periods = -2) # 数据前移
# ⽇期移动
ts.shift(periods = 2,freq = pd.tseries.offsets.Day()) # 天移动
ts.shift(periods = 1,freq = pd.tseries.offsets.MonthOffset()) #⽉移动 13.3 时间序列常⽤⽅法在做时间序列相关的⼯作时,经常要对时间做⼀些移动/滞后、频率转换、采样等相关操作,我们来看下这些操作如何使⽤index = pd.date_range('8/1/2020', periods=365, freq='D')
ts = pd.Series(np.random.randint(0, 500, len(index)), index=index)
# 1、移动
ts.shift(periods = 2) # 数据后移
ts.shift(periods = -2) # 数据前移
# ⽇期移动
ts.shift(periods = 2,freq = pd.tseries.offsets.Day()) # 天移动
ts.shift(periods = 1,freq = pd.tseries.offsets.MonthOffset()) #⽉移动
 # 2、频率转换
ts.asfreq(pd.tseries.offsets.Week()) # 天变周
ts.asfreq(pd.tseries.offsets.MonthEnd()) # 天变⽉
ts.asfreq(pd.tseries.offsets.Hour(),fill_value = 0) #天变⼩时,⼜少变多,fill_value为填充值
# 3、重采样
# resample 表示根据⽇期维度进⾏数据聚合,可以按照分钟、⼩时、⼯作⽇、周、⽉、年等来作为⽇期维度
ts.resample('2W').sum() # 以2周为单位进⾏汇总
ts.resample('3M').sum().cumsum() # 以季度为单位进⾏汇总
# 4、DataFrame重采样
d = dict({'price': [10, 11, 9, 13, 14, 18, 17, 19],
'volume': [50, 60, 40, 100, 50, 100, 40, 50],
'week_starting':pd.date_range('24/08/2020',periods=8,freq='W')})
df1 = pd.DataFrame(d)
df1.resample('M',on = 'week_starting').apply(np.sum)
df1.resample('M',on = 'week_starting').agg({'price':np.mean,'volume':np.sum})
days = pd.date_range('1/8/2020', periods=4, freq='D')
data2 = dict({'price': [10, 11, 9, 13, 14, 18, 17, 19],
'volume': [50, 60, 40, 100, 50, 100, 40, 50]})
df2 = pd.DataFrame(data2,index=pd.MultiIndex.from_product([days, ['morning','afternoon']]))
df2.resample('D', level=0).sum() # 2、频率转换
ts.asfreq(pd.tseries.offsets.Week()) # 天变周
ts.asfreq(pd.tseries.offsets.MonthEnd()) # 天变⽉
ts.asfreq(pd.tseries.offsets.Hour(),fill_value = 0) #天变⼩时,⼜少变多,fill_value为填充值
# 3、重采样
# resample 表示根据⽇期维度进⾏数据聚合,可以按照分钟、⼩时、⼯作⽇、周、⽉、年等来作为⽇期维度
ts.resample('2W').sum() # 以2周为单位进⾏汇总
ts.resample('3M').sum().cumsum() # 以季度为单位进⾏汇总
# 4、DataFrame重采样
d = dict({'price': [10, 11, 9, 13, 14, 18, 17, 19],
'volume': [50, 60, 40, 100, 50, 100, 40, 50],
'week_starting':pd.date_range('24/08/2020',periods=8,freq='W')})
df1 = pd.DataFrame(d)
df1.resample('M',on = 'week_starting').apply(np.sum)
df1.resample('M',on = 'week_starting').agg({'price':np.mean,'volume':np.sum})
days = pd.date_range('1/8/2020', periods=4, freq='D')
data2 = dict({'price': [10, 11, 9, 13, 14, 18, 17, 19],
'volume': [50, 60, 40, 100, 50, 100, 40, 50]})
df2 = pd.DataFrame(data2,index=pd.MultiIndex.from_product([days, ['morning','afternoon']]))
df2.resample('D', level=0).sum()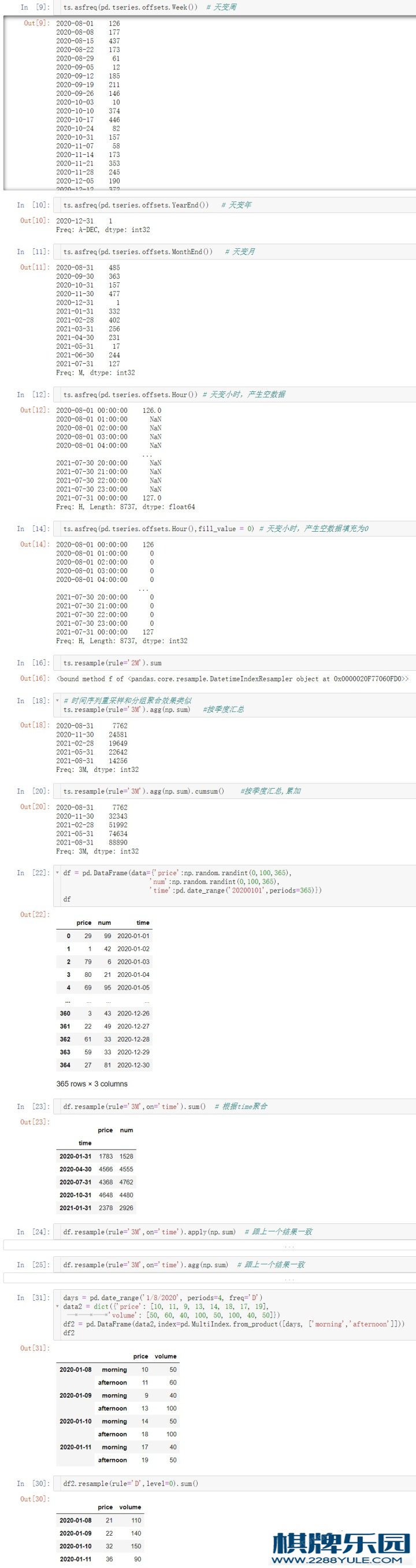 13.4 时区表示index = pd.date_range('8/1/2012 00:00', periods=5, freq='D')
ts = pd.Series(np.random.randn(len(index)), index)
import pytz
pytz.common_timezones # 常⽤时区
# 时区表示
ts = ts.tz_localize(tz='UTC')
# 转换成其它时区
ts.tz_convert(tz = 'Asia/Shanghai')14 数据可视化pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simpleimport numpy as np
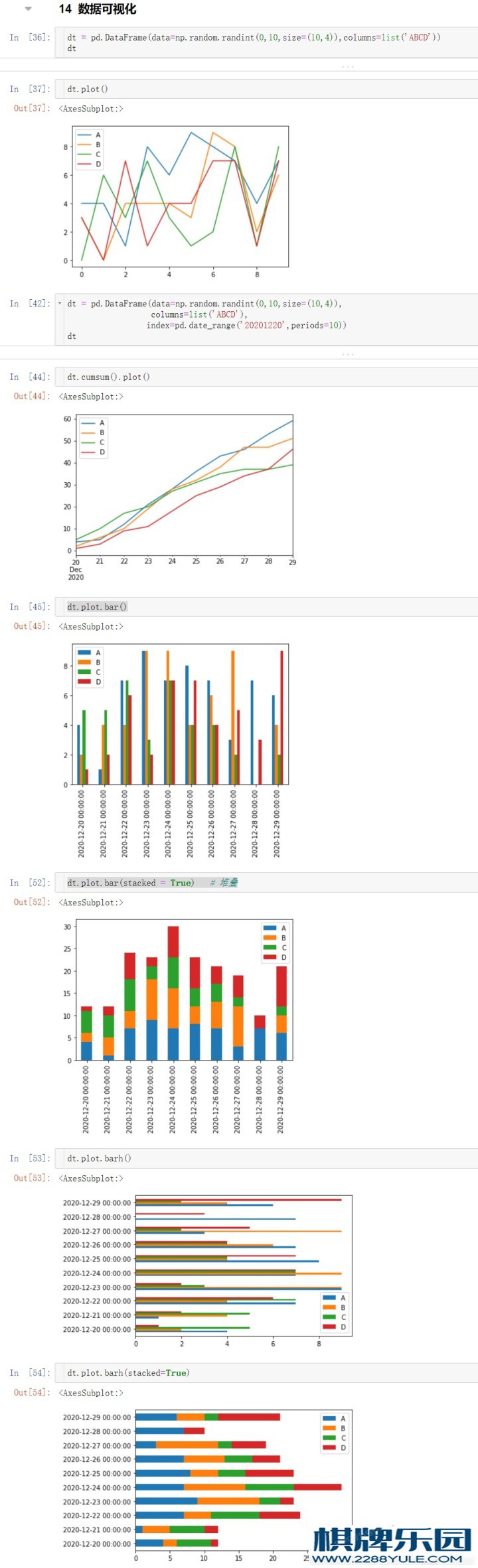
import pandas as pd
# 1、线形图
df1 = pd.DataFrame(data = np.random.randn(1000,4),
index = pd.date_range(start = '27/6/2012',periods=1000),
columns=list('ABCD'))
df1.cumsum().plot()
# 2、条形图
df2 = pd.DataFrame(data = np.random.rand(10,4),
columns = list('ABCD'))
df2.plot.bar(stacked = True) # stacked 是否堆叠
13.4 时区表示index = pd.date_range('8/1/2012 00:00', periods=5, freq='D')
ts = pd.Series(np.random.randn(len(index)), index)
import pytz
pytz.common_timezones # 常⽤时区
# 时区表示
ts = ts.tz_localize(tz='UTC')
# 转换成其它时区
ts.tz_convert(tz = 'Asia/Shanghai')14 数据可视化pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simpleimport numpy as np
import pandas as pd
# 1、线形图
df1 = pd.DataFrame(data = np.random.randn(1000,4),
index = pd.date_range(start = '27/6/2012',periods=1000),
columns=list('ABCD'))
df1.cumsum().plot()
# 2、条形图
df2 = pd.DataFrame(data = np.random.rand(10,4),
columns = list('ABCD'))
df2.plot.bar(stacked = True) # stacked 是否堆叠
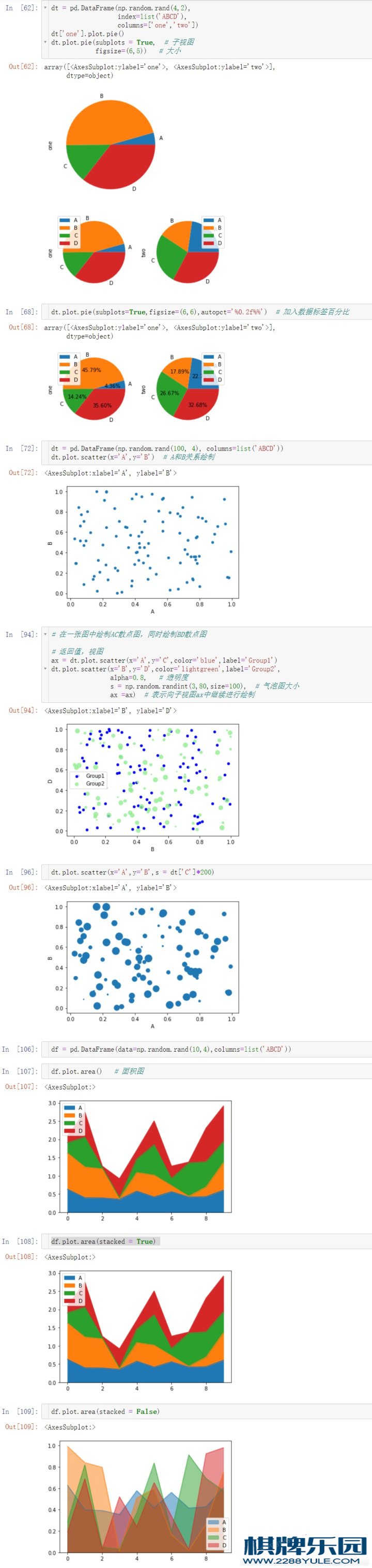
 # 3、饼图
df3 = pd.DataFrame(data = np.random.rand(4,2),
index = list('ABCD'),
columns=['One','Two'])
df3['one'].plot.pie() # 画出one的饼图
df3.plot.pie(subplots = True,figsize = (8,8))
dt.plot.pie(subplots=True,figsize=(6,6),autopct='%0.2f%%') # 加入数据标签百分比
# 4、散点图
df4 = pd.DataFrame(np.random.rand(50, 4), columns=list('ABCD'))
df4.plot.scatter(x='A', y='B') # A和B关系绘制
# 在⼀张图中绘制AC散点图,同时绘制BD散点图
ax = df4.plot.scatter(x='A', y='C', color='DarkBlue', label='Group 1');
df4.plot.scatter(x='B',y='D',color='lightgreen',label='Group2',
alpha=0.8, # 透明度
s = np.random.randint(3,80,size=100), # 气泡图大小
ax = ax) # 表示向子视图ax中继续进行绘制
# ⽓泡图,散点有⼤⼩之分
df4.plot.scatter(x='A',y='B',s = df4['C']*200)
# 5、⾯积图
df5 = pd.DataFrame(data = np.random.rand(10, 4),
columns=list('ABCD'))
df5.plot.area(stacked = False); # stacked 是否堆叠,默认True可以省略
# 3、饼图
df3 = pd.DataFrame(data = np.random.rand(4,2),
index = list('ABCD'),
columns=['One','Two'])
df3['one'].plot.pie() # 画出one的饼图
df3.plot.pie(subplots = True,figsize = (8,8))
dt.plot.pie(subplots=True,figsize=(6,6),autopct='%0.2f%%') # 加入数据标签百分比
# 4、散点图
df4 = pd.DataFrame(np.random.rand(50, 4), columns=list('ABCD'))
df4.plot.scatter(x='A', y='B') # A和B关系绘制
# 在⼀张图中绘制AC散点图,同时绘制BD散点图
ax = df4.plot.scatter(x='A', y='C', color='DarkBlue', label='Group 1');
df4.plot.scatter(x='B',y='D',color='lightgreen',label='Group2',
alpha=0.8, # 透明度
s = np.random.randint(3,80,size=100), # 气泡图大小
ax = ax) # 表示向子视图ax中继续进行绘制
# ⽓泡图,散点有⼤⼩之分
df4.plot.scatter(x='A',y='B',s = df4['C']*200)
# 5、⾯积图
df5 = pd.DataFrame(data = np.random.rand(10, 4),
columns=list('ABCD'))
df5.plot.area(stacked = False); # stacked 是否堆叠,默认True可以省略
# 6、箱式图
df6 = pd.DataFrame(data = np.random.rand(10, 5),
columns=list('ABCDE'))
df6.plot.box()
# 7、直⽅图
df7 = pd.DataFrame({'A': np.random.randn(1000) + 1,
'B': np.random.randn(1000),
'C': np.random.randn(1000) - 1})
df7.plot.hist(alpha=0.5) #带透明度直⽅图
df7.plot.hist(stacked = True)# 堆叠图
df7.hist(figsize = (8,8)) # ⼦视图绘制
# 6、箱式图
df6 = pd.DataFrame(data = np.random.rand(10, 5),
columns=list('ABCDE'))
df6.plot.box()
# 7、直⽅图
df7 = pd.DataFrame({'A': np.random.randn(1000) + 1,
'B': np.random.randn(1000),
'C': np.random.randn(1000) - 1})
df7.plot.hist(alpha=0.5) #带透明度直⽅图
df7.plot.hist(stacked = True)# 堆叠图
df7.hist(figsize = (8,8)) # ⼦视图绘制
|
Powered by 真人麻将游戏 @2013-2022 RSS地图 HTML地图
网站统计——








