
知乎上关于隐马尔科夫模型的科普非常详细了。可以直接参考这个问题下面大神们的回答。如何用简单易懂的例子解释隐马尔可夫模型? - 数学中文互联网上关于隐马模型在股票上的应用,基本都直接或间接引用了广发证券的2010年的一篇照理不应该公开的报告。知乎上面的就有:陈小米 的 【研究】西蒙斯的赚钱秘籍:隐马尔科夫模型(HMM)的择时应用 - 神秘的宽客们 - 知乎专栏江嘉键 的 隐马尔科夫链模型对于沪深300指数建模的进一步研究 - 机器学习 & 金融量化分析 - 知乎专栏LIKE 的 隐马(HMM)在股票上的简单应用 - 2 - Moneycode - 知乎专栏仔细翻一遍,这几篇文章启发性的从不同的角度论证了同一件事情:HMM是可以对沪深300指数进行解释的。比如说,我们用一个最简单的HMM 来对全部的CSI 300 指数本身的日涨跌幅进行建模:三个隐藏状态,各自为高斯分布N(1%, 1%)、N(0%, 1%)、N(-1%, 1.5%), 对应涨、平、跌。用B-W算法,或者极大似然估计,马上可以得到一张漂亮的识别图,像下图这样。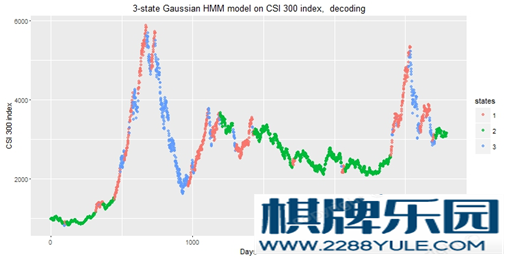 不过,这几篇文章里讲到的收益率都在用未来的数据去预测未来,因此在预测方面参考价值不大。另一个问题是,把所有的历史数据加入模型的拟合之中,不大可能会获得稳定的超额收益,不然Fama 可能要对中国股市摇摇头了。笔者翻阅了一些关于HMM在股市上应用的英文文献,和预测相关的几篇都强调了dynamic pool 的重要性:即仅使用一部分最近的数据来预测下一天的走势。然后再第二天收盘时候去掉第一天的数据,再引入下一天的数据,重新拟合模型。我的硕士论文正好也涉及了类似的话题,在这里简单引申一下。首先,我们依然只对沪深300的每日收益率建模(我很想对四个指标做多元HMM。但是我用的R包HiddenMarkov 只支持uni-variate HMM,实在是没有动力大幅修改代码)。下图所示的2971天是05年1月4日至16年6月30日的沪深300每日收益率。用每L天去预测下一天的走势。这里的L 经过测试,大概选在100-140左右是最合理的,即大约半年的交易日总数。为了运行起来方便一点,我们依然只选3个隐状态,各自用一个正态分布表示。由于每个模型的信息量比较小,所以拟合算法经常收敛失败,同时存在比较严重的local maximum 问题。所以,对每一段数据,我们都用不一样的随机初始值跑10000次拟合,然后选择有最大似然值的那个HMM来解释这段数据。完成一个模型以后,我们就可以用拟合后的参数作为下一个模型的初始值了。 不过,这几篇文章里讲到的收益率都在用未来的数据去预测未来,因此在预测方面参考价值不大。另一个问题是,把所有的历史数据加入模型的拟合之中,不大可能会获得稳定的超额收益,不然Fama 可能要对中国股市摇摇头了。笔者翻阅了一些关于HMM在股市上应用的英文文献,和预测相关的几篇都强调了dynamic pool 的重要性:即仅使用一部分最近的数据来预测下一天的走势。然后再第二天收盘时候去掉第一天的数据,再引入下一天的数据,重新拟合模型。我的硕士论文正好也涉及了类似的话题,在这里简单引申一下。首先,我们依然只对沪深300的每日收益率建模(我很想对四个指标做多元HMM。但是我用的R包HiddenMarkov 只支持uni-variate HMM,实在是没有动力大幅修改代码)。下图所示的2971天是05年1月4日至16年6月30日的沪深300每日收益率。用每L天去预测下一天的走势。这里的L 经过测试,大概选在100-140左右是最合理的,即大约半年的交易日总数。为了运行起来方便一点,我们依然只选3个隐状态,各自用一个正态分布表示。由于每个模型的信息量比较小,所以拟合算法经常收敛失败,同时存在比较严重的local maximum 问题。所以,对每一段数据,我们都用不一样的随机初始值跑10000次拟合,然后选择有最大似然值的那个HMM来解释这段数据。完成一个模型以后,我们就可以用拟合后的参数作为下一个模型的初始值了。  对每段数据建模以后,我们要对下一个日期的股指走势进行预测(上图中的橙色点)预测的原理涉及到 forward-backward algorithm,即解决HMM三大问题中的评估问题的那一个算法。中文互联网上我能找到最好的科普来自52nlp(HMM相关文章索引)。简单的说,就是通过给定的模型,和给定的数据链,去计算下一个时间点各个隐藏状态出现的可能性。计算公式如下图。 其中,lamda 是HMM模型,O 是数据链,alpha 是forward probability, pi 是状态转移矩阵, L 是似然值。 对每段数据建模以后,我们要对下一个日期的股指走势进行预测(上图中的橙色点)预测的原理涉及到 forward-backward algorithm,即解决HMM三大问题中的评估问题的那一个算法。中文互联网上我能找到最好的科普来自52nlp(HMM相关文章索引)。简单的说,就是通过给定的模型,和给定的数据链,去计算下一个时间点各个隐藏状态出现的可能性。计算公式如下图。 其中,lamda 是HMM模型,O 是数据链,alpha 是forward probability, pi 是状态转移矩阵, L 是似然值。 用三个概率,加权平均每个状态的正态分布的平均数,为正的话则为买入信号,为负的话则为卖出信号。得到收益曲线如下。上图是仅买入。下图加入简单做空。年收益31%左右。但是夏普率并不是很好看,仅仅略高于大盘。如果算出加权的标准差,则可以算出一个置信区间,来看看每个预测的信心程度。排除那些不确信的预测(接近0且大方差),夏普率会上升一些,收益基本保持不变。 用三个概率,加权平均每个状态的正态分布的平均数,为正的话则为买入信号,为负的话则为卖出信号。得到收益曲线如下。上图是仅买入。下图加入简单做空。年收益31%左右。但是夏普率并不是很好看,仅仅略高于大盘。如果算出加权的标准差,则可以算出一个置信区间,来看看每个预测的信心程度。排除那些不确信的预测(接近0且大方差),夏普率会上升一些,收益基本保持不变。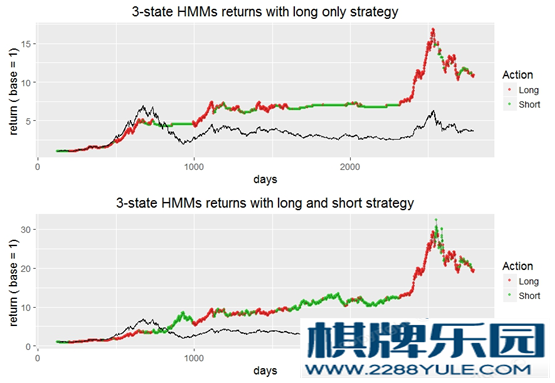 上面这些只是野路子探索,佐证了一下HMM的普适性。如果我们回到广发的那篇文章,就会发现它其实棋牌资讯用的是语音识别的思路,跟前述三篇文章和上面这部分内容关系不大。广发的文章里,首先介绍了语音识别。语音识别分成两步:拟合与识别。在第一步拟合,我们需要一个很大的train dataset。然后把里面的语音分成一个个特征小段。然后对每个特征小段拟合一个合适的HMM。第二步是识别,读一个新的test 句子给他,也分成一段一段,然后每一段全部扔进之前所有的HMM里,找到有最大似然值的那一个(或几个)音节,作为这一段的识别结果,然后拼起来。 上面这些只是野路子探索,佐证了一下HMM的普适性。如果我们回到广发的那篇文章,就会发现它其实棋牌资讯用的是语音识别的思路,跟前述三篇文章和上面这部分内容关系不大。广发的文章里,首先介绍了语音识别。语音识别分成两步:拟合与识别。在第一步拟合,我们需要一个很大的train dataset。然后把里面的语音分成一个个特征小段。然后对每个特征小段拟合一个合适的HMM。第二步是识别,读一个新的test 句子给他,也分成一段一段,然后每一段全部扔进之前所有的HMM里,找到有最大似然值的那一个(或几个)音节,作为这一段的识别结果,然后拼起来。 (我感觉这里有很多问题。但我不是语音识别的专家。如果说这篇文章在报道上出现的偏差,我是不会负责的。知乎上有大神写了关于HMM在语音识别上的应用科普,有兴趣的可以搜一下。)同理应用到沪深300股指上去。首先把沪深300股指的四个参数指标,按时间分成很多小段,像语音识别中的音节一样。然后每个小段拟合一个最好的HMM出来。第二步,就是拿最近的一个时间段扔回之前所有的HMM中去,找到极大似然的一段或者n段,作为识别。策略的思路依然很简单:历史在不断重复自己。过去发生过的行情走势,会在未来不断重复。所以针对最近的走势去预测明天的股市,我们先直接去找历史上最相似的走势,然后看看它后来是怎么走的就好了。语音识别是把语音识别出来,告诉用户,就好了。我们这里则需要在识别出来以后,再多一步对股指的预测。广发的这篇文章把这一段给省略了,直接告诉我们识别完会输出一个涨和跌的投资信号。这里可能藏了一个重点。在我的实验里,预测方法不同带来的准确率差别极大。基本思路有这两个:还是用forward-backward algorithm 进行state prediction,然后看对应正态分布的mean 和sd 是否给出明确的上涨或下跌信息。第二种预测方法,对所识别出的历史图形(们)的接下来3天(不一定是3)的走势进行加权平均(见下图),来看未来走势是否明确。这篇文章给出了一种很不错的加权方法,即更近日期的值拥有更大的weight。 (我感觉这里有很多问题。但我不是语音识别的专家。如果说这篇文章在报道上出现的偏差,我是不会负责的。知乎上有大神写了关于HMM在语音识别上的应用科普,有兴趣的可以搜一下。)同理应用到沪深300股指上去。首先把沪深300股指的四个参数指标,按时间分成很多小段,像语音识别中的音节一样。然后每个小段拟合一个最好的HMM出来。第二步,就是拿最近的一个时间段扔回之前所有的HMM中去,找到极大似然的一段或者n段,作为识别。策略的思路依然很简单:历史在不断重复自己。过去发生过的行情走势,会在未来不断重复。所以针对最近的走势去预测明天的股市,我们先直接去找历史上最相似的走势,然后看看它后来是怎么走的就好了。语音识别是把语音识别出来,告诉用户,就好了。我们这里则需要在识别出来以后,再多一步对股指的预测。广发的这篇文章把这一段给省略了,直接告诉我们识别完会输出一个涨和跌的投资信号。这里可能藏了一个重点。在我的实验里,预测方法不同带来的准确率差别极大。基本思路有这两个:还是用forward-backward algorithm 进行state prediction,然后看对应正态分布的mean 和sd 是否给出明确的上涨或下跌信息。第二种预测方法,对所识别出的历史图形(们)的接下来3天(不一定是3)的走势进行加权平均(见下图),来看未来走势是否明确。这篇文章给出了一种很不错的加权方法,即更近日期的值拥有更大的weight。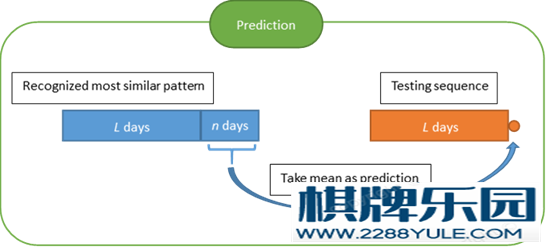 (不得不说,这两种预测方法都需要大量的实验去确定那些细小参数的最佳值,增大了模型的复杂程度,所以肯定是有瑕疵的。)我尝试在R上复制了一下这个策略。下面是实验内容。取2005年1月4日后2000天的数据作train dataset,其间总计1971个30天的training window。2000天以后到2016年6月30日的791天做test,其间一共761个test window。取2000作为分隔点不仅为了方便,也因为左右两边各有震荡,大涨,大跌行情出现过。我在这里给一些识别的结果(仅使用获得最大似然值的历史走势,而不是多个类似历史走势加权)。 (不得不说,这两种预测方法都需要大量的实验去确定那些细小参数的最佳值,增大了模型的复杂程度,所以肯定是有瑕疵的。)我尝试在R上复制了一下这个策略。下面是实验内容。取2005年1月4日后2000天的数据作train dataset,其间总计1971个30天的training window。2000天以后到2016年6月30日的791天做test,其间一共761个test window。取2000作为分隔点不仅为了方便,也因为左右两边各有震荡,大涨,大跌行情出现过。我在这里给一些识别的结果(仅使用获得最大似然值的历史走势,而不是多个类似历史走势加权)。 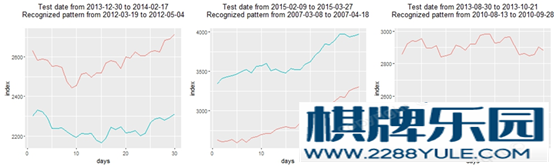  没有仔细调细节参数(拟合的初始值,识别和预测的加权概率等等),这个模型的预测准确率在55%左右。如前所述,这是仅仅对股指每日收益率进行建模的结果。如果引入另外三个正交参数,识别结果应当会非常可观。广发给出的模型预测涨跌准确率在60%以上。然后进行一个简单的751天的做多回测,不考虑手续费。在这个一个震荡-涨-跌-震荡的周期里,做多收益率2倍左右。加入简单做空,收益率上升到2.4。夏普率均高于大盘。 没有仔细调细节参数(拟合的初始值,识别和预测的加权概率等等),这个模型的预测准确率在55%左右。如前所述,这是仅仅对股指每日收益率进行建模的结果。如果引入另外三个正交参数,识别结果应当会非常可观。广发给出的模型预测涨跌准确率在60%以上。然后进行一个简单的751天的做多回测,不考虑手续费。在这个一个震荡-涨-跌-震荡的周期里,做多收益率2倍左右。加入简单做空,收益率上升到2.4。夏普率均高于大盘。 就广发证券的报告和我这里简单的探索来看,这个模型应当是值得花一些时间去打磨的。可改进的地方非常多。一是引入多因子分析,建立多元模型(就像上面几篇文章做的那样。python上有现成的代码可以借鉴。当然R也有几个多元HMM的包,如msm);二是确定怎样的HMM能更好的表述每个数据链的特征, 包括各种初始值的设定;三是找到一个经验上和实验上都说得通的预测方法;四是把模型更好结合到现实的交易中:有几篇英文文献提到,隐马尔科夫模型其实更适合应用于小盘个股上,因为投资者的关注度本身就是一个很好的隐状态feature。在此我就抛砖引玉了。图片版权均系作者所有。转载须注明作者。PS 笔者系圣安德鲁斯大学统计学硕士应届毕业生。正在寻求16年9月以后的量化分析实习机会,不限地区。望有相关信息的朋友私信我。多谢! 就广发证券的报告和我这里简单的探索来看,这个模型应当是值得花一些时间去打磨的。可改进的地方非常多。一是引入多因子分析,建立多元模型(就像上面几篇文章做的那样。python上有现成的代码可以借鉴。当然R也有几个多元HMM的包,如msm);二是确定怎样的HMM能更好的表述每个数据链的特征, 包括各种初始值的设定;三是找到一个经验上和实验上都说得通的预测方法;四是把模型更好结合到现实的交易中:有几篇英文文献提到,隐马尔科夫模型其实更适合应用于小盘个股上,因为投资者的关注度本身就是一个很好的隐状态feature。在此我就抛砖引玉了。图片版权均系作者所有。转载须注明作者。PS 笔者系圣安德鲁斯大学统计学硕士应届毕业生。正在寻求16年9月以后的量化分析实习机会,不限地区。望有相关信息的朋友私信我。多谢!
其实,玩家们若是想要知道怎么打麻将游戏更加的刺激,玩家们只要知道了麻将游戏的技巧,那么也就知道要怎么去打麻将才可以感受到游戏的刺激感了。其实麻将游戏是一款需要玩家们掌握游戏的技巧的游戏,也就是说玩家们如果是不带着游戏的技巧去进行麻将游戏的话,那么玩家们是不可以赢得游戏的。既然说了玩家们不可能会赢得麻将游戏,那么也就是说明了玩家们无法从麻将游戏当中获取到游戏的刺激感,这样也就不可能感受到刺激的感觉了。 |
Powered by 真人麻将游戏 @2013-2022 RSS地图 HTML地图
网站统计——








